print_help() { echo"Usage:" echo"local.sh docker interactive [--privileged]" echo"" echo" --privileged - run a privileged container. This allows the use of KVM (if available)" echo" --allow-gui - run the docker such that it can open GUI apps" echo"" }
docker_interactive() { local full_image_name="${DEFAULT_REGISTRY}/${DEFAULT_IMAGE_NAME}:${DEFAULT_TAG}" local executable="/bin/bash" local registry=${DEFAULT_REGISTRY}
if [[ $(docker images -q $full_image_name 2> /dev/null) == "" ]]; then docker pull $full_image_name fi
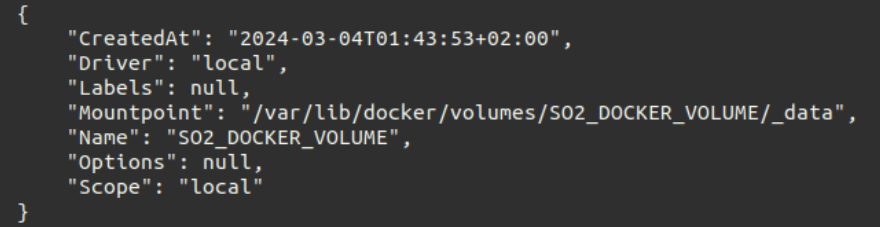
if ! docker volume inspect $SO2_VOLUME >/dev/null 2>&1; then echo"Volume $SO2_VOLUME does not exist." echo"Creating it" docker volume create $SO2_VOLUME local vol_mount=$(docker inspect $SO2_VOLUME | grep -i mountpoin | cut -d : -f2 | cut -d, -f1) chmod 777 -R $vol_mount fi
echo"The /linux directory is made persistent within the $SO2_VOLUME:" docker inspect $SO2_VOLUME
if$allow_gui; then # TODO: remove this after you change sdl to gtk in qemu-runqemu.sh docker run $privileged --rm -it --cap-add=NET_ADMIN --device /dev/net/tun:/dev/net/tun \ -v $SO2_VOLUME:/linux \ --workdir "$SO2_WORKSPACE" \ "$full_image_name" sed "s+\${QEMU_DISPLAY:-\"sdl\"+\${QEMU_DISPLAY:-\"gtk\"+g" -i /linux/tools/labs/qemu/run-qemu.sh
# wsl ifcat /proc/version | grep -i microsoft &> /dev/null ; then export DISPLAY="$(ip r show default | awk '{print $3}'):0.0" fi
if [[ $DISPLAY == "" ]]; then echo"Error: Something unexpected happend. The environment var DISPLAY is not set. Consider setting it with" echo -e "\texport DISPLAY=<dispaly>" exit 1 fi
local xauth_var=$(echo $(xauth info | grep Auth | cut -d: -f2)) docker run --privileged --rm -it \ --net=host --env="DISPLAY" --volume="${xauth_var}:/root/.Xauthority:rw" \ -v $SO2_VOLUME:/linux \ --workdir "$SO2_WORKSPACE" \ "$full_image_name""$executable" else docker run $privileged --rm -it --cap-add=NET_ADMIN --device /dev/net/tun:/dev/net/tun \ -v $SO2_VOLUME:/linux \ --workdir "$SO2_WORKSPACE" \ "$full_image_name""$executable" fi
}
docker_main() { if [ "$1" = "interactive" ] ; then shift docker_interactive "$@" fi }
if [ "$1" = "docker" ] ; then shift docker_main "$@" elif [ "$1" = "-h" ] || [ "$1" = "--help" ]; then print_help else print_help fi
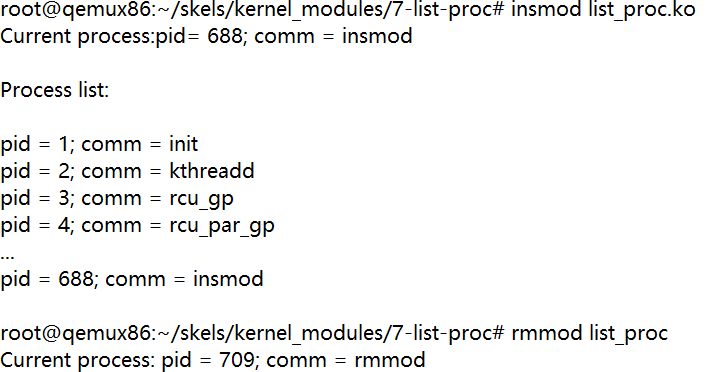
执行 root@ubuntu20:/linux/tools/labs/skels/kernel_modules/7-list-proc# vim list_proc.c 命令,修改 list_proc.c 文件源代码
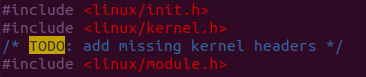
在注释TO DO处添加如下代码
1 2 3 4 5 6 7 8 9 10 11 12
/* TODO: add missing headers */ #include<linux/sched/signal.h> /* TODO/2: print current process pid and its name */ pr_info("Current process: pid = %d; comm = %s\n", current->pid, current->comm); /* TODO/3: print the pid and name of all processes */ pr_info("\nProcess list:\n\n"); for_each_process(p) pr_info("pid = %d; comm = %s\n", p->pid, p->comm); /* TODO/2: print current process pid and name */ pr_info("Current process: pid = %d; comm = %s\n", current->pid, current->comm);
/* TODO 1/2: Allocate task_info and add it to list */ // 分配内存给ti变量,ti是一个task_info结构体指针,描述任务信息(这里指描述当前进程的PID和时间) ti = task_info_alloc(pid); // 将ti添加到链表,注意list_add函数的用法,传入的是ti->list的地址和head的地址(没有使用结构体指针) list_add(&ti->list, &head); }
staticvoidtask_info_add_for_current(void) { /* Add current, parent, next and next of next to the list */ task_info_add_to_list(current->pid); task_info_add_to_list(current->parent->pid); task_info_add_to_list(next_task(current)->pid); task_info_add_to_list(next_task(next_task(current))->pid); }
/* TODO 2/5: Iterate over the list and delete all elements */ // 这里要注意,list_for_each_safe是一个宏而不是函数,不要加分号 list_for_each_safe(p, q, &head) { // list_entry是找到当前链表节点相对应的原来的结构体指针变量,即映射回去 ti = list_entry(p, struct task_info, list); list_del(p); kfree(ti); } }
知识点
list_entry(ptr, type, member)() 返回列表中包含元素 ptr 的类型为 type 的结构,该结构中具有名为 member 的成员。
list_for_each(pos, head) 使用 pos 作为游标来迭代列表。
list_for_each_safe(pos, n, head) 使用 pos 作为游标,n 作为临时游标来迭代列表。此宏用于从列表中删除项目。
/* TODO 1/5: Look for pid and return task_info or NULL if not found */ // 找到成员pid值等于参数pid值的链表节点ti list_for_each(p, &head) { ti = list_entry(p, struct task_info, list); if (ti->pid == pid) return ti; }
/* TODO 2/2: Ensure that at least one task is not deleted */ // 这里要学会使用原子操作函数atomic_set,原子操作是一种不会被打断必定执行的操作,必须使用原子变量atomic_t ti = list_entry(head.prev, struct task_info, list); atomic_set(&ti->count, 10);
/* TODO 1/6: register char device region for MY_MAJOR and NUM_MINORS starting at MY_MINOR */ err = register_chrdev_region(MKDEV(MY_MAJOR, MY_MINOR), NUM_MINORS, MODULE_NAME); /* TODO 1/1: unregister char device region, for MY_MAJOR and NUM_MINORS starting at MY_MINOR */ unregister_chrdev_region(MKDEV(MY_MAJOR, MY_MINOR),NUM_MINORS);
structso2_device_data { /* TODO 2/1: add cdev member */ structcdevcdev; /* TODO 4/2: add buffer with BUFSIZ elements */ char buffer[BUFSIZ]; size_t size; /* TODO 7/2: extra members for home */ wait_queue_head_t wq; int flag; /* TODO 3/1: add atomic_t access variable to keep track if file is opened */ atomic_t access; };
为当前设备文件建立一个结构体,成员有cdev结构体,该结构体用于在系统中注册字符设备(供cdev_init和cdev_add函数使用),字符数组buffer用于读操作,size用于指示传输数据的大小,access是一个原子变量,用于计数实现阻塞其它进程干涉,这里只需要关注 TODO 2/1
实现打开和释放函数
1 2 3 4 5 6 7 8 9 10 11
// 在结构体定义static const struct file_operations so2_fops中 /* TODO 2/2: add open and release functions */ .open = so2_cdev_open, .release = so2_cdev_release,
// 在函数so2_cdev_open中 /* TODO 3/1: inode->i_cdev contains our cdev struct, use container_of to obtain a pointer to so2_device_data */ // 获取当前设备文件的结构体 data = container_of(inode->i_cdev, struct so2_device_data, cdev); // 让file指针指向当前设备文件,实现打开 file->private_data = data;
// 在结构体so2_device_data中 /* TODO 3/1: add atomic_t access variable to keep track if file is opened */ atomic_t access;
在模块初始化时对该变量进行初始化
1 2 3 4 5
// 在函数so2_cdev_init中 /* TODO 3/1: set access variable to 0, use atomic_set */ atomic_set(&devs[i].access, 0); // 这里的devs是设备文件的实例化,在设备文件结构体下有定义 // struct so2_device_data devs[NUM_MINORS];
在打开函数中使用该变量限制对设备的访问。我们建议使用 atomic_cmpxchg()
1 2 3 4
// 在函数so2_cdev_open中 /* TODO 3/2: return immediately if access is != 0, use atomic_cmpxchg */ if (atomic_cmpxchg(&data->access, 0, 1) != 0) return -EBUSY;
static inline int atomic_cmpxchg(atomic_t *ptr, int old, int new) 这个函数可以在一个原子操作中检查变量的旧值并将其设为新值,在上面的例子中,它表示如果当前的access等于旧值0就将access设为1,不等于0就不修改,无论是否发生替换,atomic_cmpxchg函数都会返回ptr指向的原始值(也就是操作之前的值)。
在释放函数中重置该变量以恢复对设备的访问权限
1 2 3
// 在函数so2_cdev_release中 /* TODO 3/1: reset access variable to 0, use atomic_set */ atomic_set(&data->access, 0);
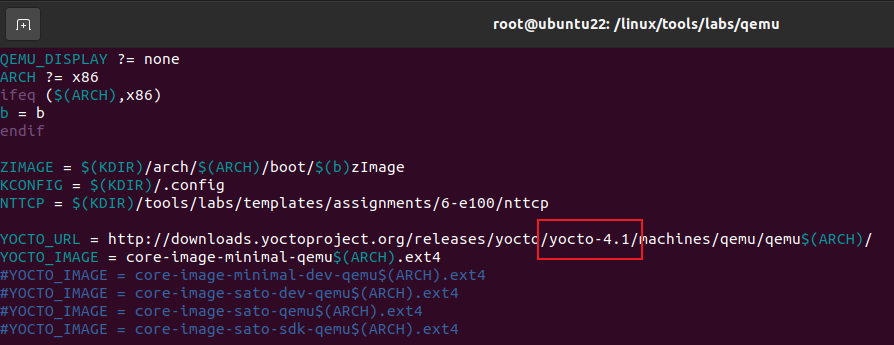
按照“注意”的提示使用 QEMU_DISPLAY=gtk make boot 是无法启动成功的,因为QEMU中的Makefile指定需要下载yotco2.4版本的镜像系统,但是链接早就失效了,必须修改QEMU中的Makefile的yotco版本号为4.1才能正常下载系统镜像从而启动,如下图所示修改,如果下载的很慢或者还是下载不了,可能需要使用代理,使用clash-verge的TUN模式可以让虚拟机走代理
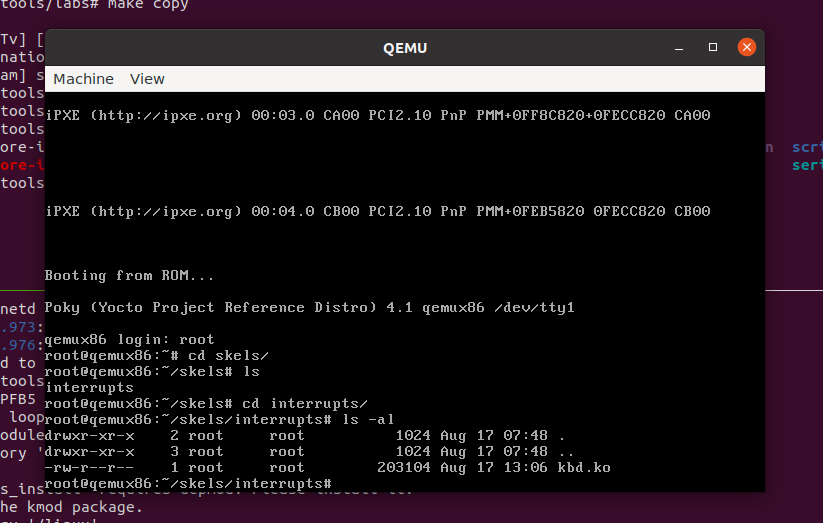
没有报错之后应该能正常启动系统,如下所示
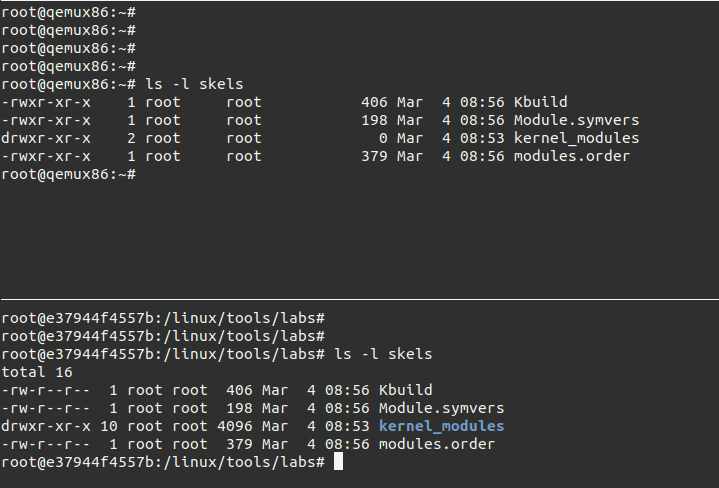
但此时要退出来,因为没有在Docker内执行 make copy,执行前系统内是没有 skels 这个文件夹的
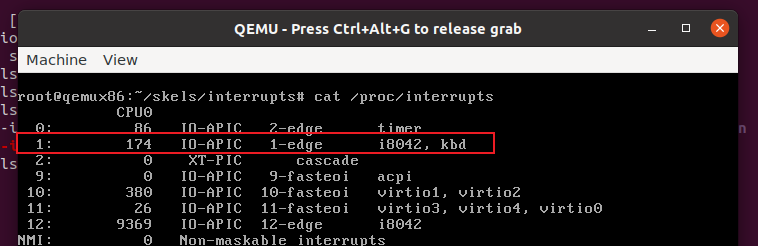
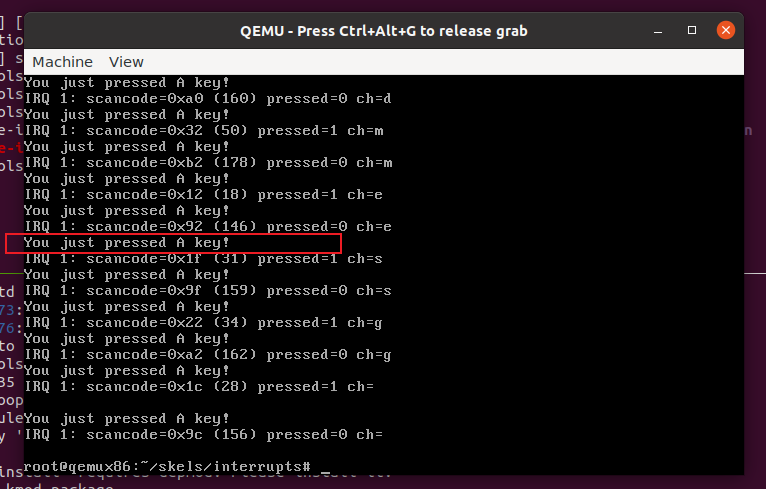
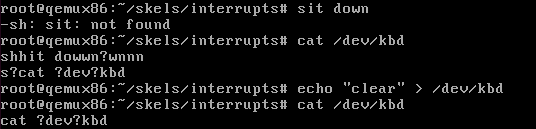
在QEMU中按下键盘按键会触发中断例程程序,使用dmesg可以看到:
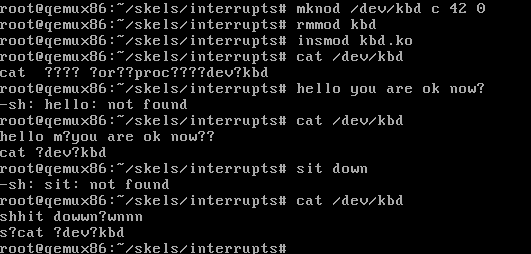
3.将 ASCII 键存储到缓冲区
读取数据存储器
1 2 3 4 5 6 7 8 9 10 11
// 使用函数 inb 读取 I/O 端口的数据,只读一个字符大小的数据(1 Byte) staticinline u8 i8042_read_data(void) { u8 val; /* TODO 3: Read DATA register (8 bits). */ val = inb(I8042_DATA_REG); // 此时读取的是寄存器中的扫描码,还需要转换才能成为ASCII码 return val; } // 在 kbd_interrupt_handle 函数中 /* TODO 3: read the scancode */ scancode = i8042_read_data();
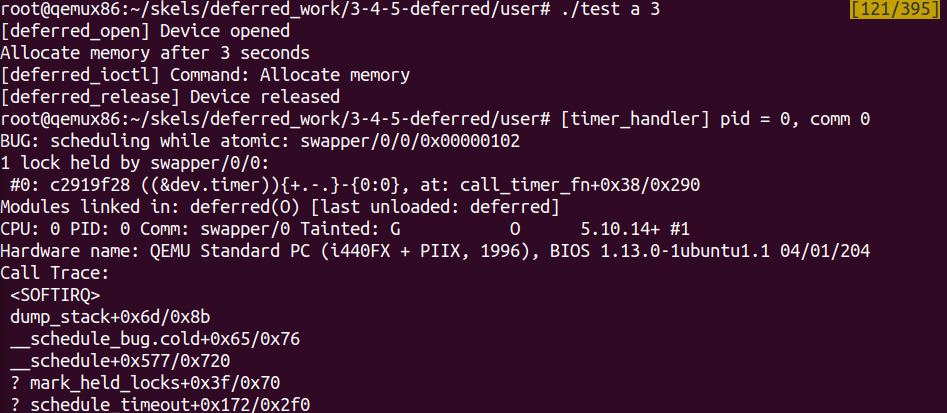
// 1.为了区分定时器处理程序中的功能,在设备结构体中添加flag字段 /* TODO 2: add flag */ int flag; // 2.在定时器处理程序中,为不同的flag设置不同的功能 /* TODO 2/38: check flags: TIMER_TYPE_SET or TIMER_TYPE_ALLOC */ switch (my_data->flag) { case TIMER_TYPE_SET: break; case TIMER_TYPE_ALLOC: #ifdef ALLOC_IO_DIRECT alloc_io(); #else #endif break; default: break; } // 3.设置不同参数下的中断程序标志 case MY_IOCTL_TIMER_SET: /* TODO 2: set flag */ my_data->flag = TIMER_TYPE_SET; case MY_IOCTL_TIMER_ALLOC: /* TODO 2/2: set flag and schedule timer */ my_data->flag = TIMER_TYPE_ALLOC; mod_timer(&my_data->timer, jiffies + arg * HZ); break; // 4.初始化设备flag标志位 /* TODO 2: Initialize flag. */ dev.flag = TIMER_TYPE_NONE;
// 1.初始化等待队列和标志位 /* TODO/4: init the waitqueues and flags */ init_waitqueue_head(&wq_stop_thread); atomic_set(&flag_stop_thread, 0); init_waitqueue_head(&wq_thread_terminated); atomic_set(&flag_thread_terminated, 0);
// 2.创建和开始内核线程 /* TODO: create and start the kernel thread */ kthread_run(my_thread_f, NULL, "%skthread%d", "my", 0);
// 3.定义线程处理函数 intmy_thread_f(void *data) { pr_info("[my_thread_f] Current process id is %d (%s)\n", current->pid, current->comm); // 4.等待命令去移除在等待队列中的模块 /* TODO: Wait for command to remove module on wq_stop_thread queue. */ wait_event_interruptible(wq_stop_thread,atomic_read(&flag_stop_thread) != 0);
// 5.设置标志位标记内核线程结束 /* TODO: set flag to mark kernel thread termination */ atomic_set(&flag_thread_terminated, 1);
// 6.拉起中断,通知其他进程可以上来了 /* TODO: notify the unload process that we have exited */ wake_up_interruptible(&wq_thread_terminated);
pr_info("[my_thread_f] Exiting\n"); do_exit(0); }
// 7.线程退出函数 staticvoid __exit kthread_exit(void) { /* TODO/2: notify the kernel thread that its time to exit */ atomic_set(&flag_stop_thread, 1); wake_up_interruptible(&wq_stop_thread); /* TODO: wait for the kernel thread to exit */ wait_event_interruptible(wq_thread_terminated, atomic_read(&flag_thread_terminated) != 0); pr_info("[kthread_exit] Exit module\n"); }
六 块设备驱动程序
实验目标:
了解 Linux 中 I/O 子系统的行为
在块设备的结构和函数上进行实际操作
通过解决练习,掌握块设备的 API 使用基础技能
0.简介
符号
定义位置(头文件)
简要说明
struct bio
<linux/bio.h>
块 I/O 的基本结构,包含 bio_vec 数组等
struct bio_vec
<linux/bio.h>
I/O segment 描述:页面、偏移量、长度
bio_for_each_segment
<linux/bio.h>(宏)
遍历 bio 中每个 segment 的迭代宏
struct gendisk
<linux/genhd.h>
通用磁盘结构,代表块设备抽象
struct block_device_operations
<linux/blkdev.h>
块设备操作函数集合
struct request
<linux/blkdev.h>
块 I/O 请求结构,含多个 bio
1.块设备
创建一个内核模块,允许你注册或者取消注册块设备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 1.在初始化函数中注册块设备 /* TODO 1/5: register block device */ err = register_blkdev(MY_BLOCK_MAJOR, MY_BLKDEV_NAME); if (err < 0) { printk(KERN_ERR "register_blkdev: unable to register\n"); return err; }
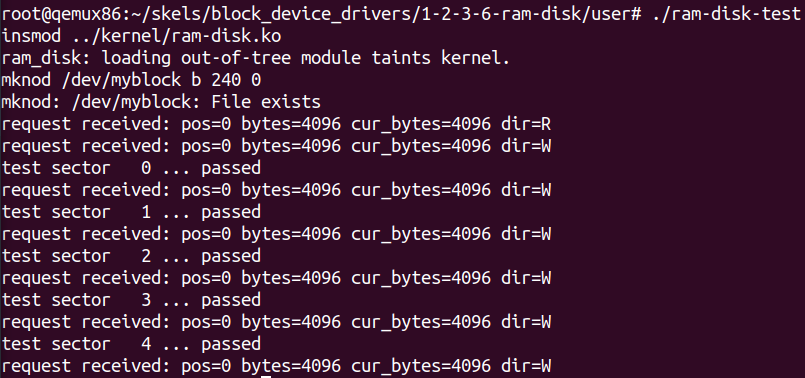
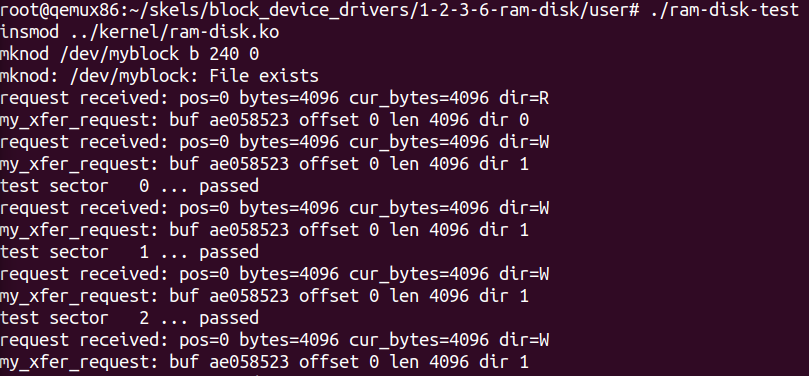
// 1.完善请求处理函数 staticblk_status_tmy_block_request(struct blk_mq_hw_ctx *hctx, conststruct blk_mq_queue_data *bd) { structrequest *rq; structmy_block_dev *dev = hctx->queue->queuedata; /* TODO 2: get pointer to request */ rq = bd->rq; /* TODO 2: start request processing. */ blk_mq_start_request(rq); /* TODO 2/5: check fs request. Return if passthrough. */ if (blk_rq_is_passthrough(rq)) { printk(KERN_NOTICE "Skip non-fs request\n"); blk_mq_end_request(rq, BLK_STS_IOERR); goto out; } /* TODO 2/6: print request information */ printk(KERN_LOG_LEVEL "request received: pos=%llu bytes=%u " "cur_bytes=%u dir=%c\n", (unsignedlonglong) blk_rq_pos(rq), blk_rq_bytes(rq), blk_rq_cur_bytes(rq), rq_data_dir(rq) ? 'W' : 'R');
#if USE_BIO_TRANSFER == 1 /* TODO 6/1: process the request by calling my_xfer_request */ #else /* TODO 3/3:process the request by calling my_block_transfer */ #endif
/* TODO 2/1: end request successfully */ blk_mq_end_request(rq, BLK_STS_OK);
out: return BLK_STS_OK; }
// 2.在初始化函数中创建块设备 /* TODO 2/3: create block device using create_block_device */ err = create_block_device(&g_dev); if (err < 0) goto out; return0; /* TODO 2/1: unregister block device in case of an error */ unregister_blkdev(MY_BLOCK_MAJOR, MY_BLKDEV_NAME);
// 3.在卸载函数中删除块设备 /* TODO 2/1: cleanup block device using delete_block_device */ delete_block_device(&g_dev);
/* check for read/write beyond end of block device */ if ((offset + len) > dev->size) return;
/* TODO 3/4: read/write to dev buffer depending on dir */ if (dir == 1) /* write */ memcpy(dev->data + offset, buffer, len); else memcpy(buffer, dev->data + offset, len); } /* TODO 3/3: process the request by calling my_block_transfer */ my_block_transfer(dev, blk_rq_pos(rq), blk_rq_bytes(rq), bio_data(rq->bio), rq_data_dir(rq));
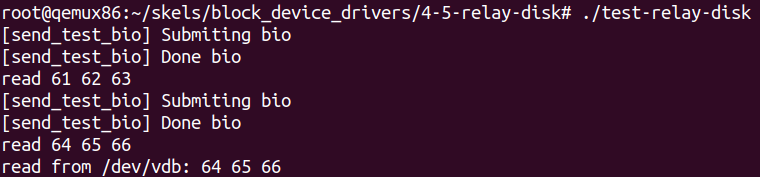
/* TODO 4/3: fill bio (bdev, sector, direction) */ bio->bi_disk = bdev->bd_disk; bio->bi_iter.bi_sector = 0; bio->bi_opf = dir; /* TODO 4/3: submit bio and wait for completion */ printk(KERN_LOG_LEVEL "[send_test_bio] Submiting bio\n"); submit_bio_wait(bio); printk(KERN_LOG_LEVEL "[send_test_bio] Done bio\n"); /* TODO 4/3: read data (first 3 bytes) from bio buffer and print it */ buf = kmap_atomic(page); printk(KERN_LOG_LEVEL "read %02x %02x %02x\n", buf[0], buf[1], buf[2]); kunmap_atomic(buf); /* TODO 4/5: get block device in exclusive mode */ bdev = blkdev_get_by_path(name, FMODE_READ | FMODE_WRITE | FMODE_EXCL, THIS_MODULE); if (IS_ERR(bdev)) { printk(KERN_ERR "blkdev_get_by_path\n"); returnNULL; } /* TODO 4/1: put block device */ blkdev_put(bdev, FMODE_READ | FMODE_WRITE | FMODE_EXCL);
5.将数据写入磁盘
在磁盘上写入消息(BIO_WRITE_MESSAGE)
1 2 3 4 5 6 7 8 9 10 11 12
/* TODO 5/5: write message to bio buffer if direction is write */ if (dir == REQ_OP_WRITE) { buf = kmap_atomic(page); memcpy(buf, BIO_WRITE_MESSAGE, strlen(BIO_WRITE_MESSAGE)); kunmap_atomic(buf); } staticvoid __exit relay_exit(void) { /* TODO 5/1: send test write bio */ send_test_bio(phys_bdev, REQ_OP_WRITE); close_disk(phys_bdev); }
6.在struct bio级别处理请求队列中的请求
处理来自请求队列中所有 struct bio 结构的所有 struct bio_vec 结构(也称为段)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* TODO 6/0: use bios for read/write requests */ #define USE_BIO_TRANSFER 1 /* TODO 6/10: iterate segments */ structbio_vecbvec; structreq_iteratoriter; rq_for_each_segment(bvec, req, iter) { sector_t sector = iter.iter.bi_sector; unsignedlong offset = bvec.bv_offset; size_t len = bvec.bv_len; int dir = bio_data_dir(iter.bio); char *buffer = kmap_atomic(bvec.bv_page); printk(KERN_LOG_LEVEL "%s: buf %8p offset %lu len %u dir %d\n", __func__, buffer, offset, len, dir); /* TODO 6/3: copy bio data to device buffer */ my_block_transfer(dev, sector, len, buffer + offset, dir); kunmap_atomic(buffer); } /* TODO 6/1: process the request by calling my_xfer_request */ my_xfer_request(dev, rq);
七 文件系统驱动程序(第一部分)
实验目标:
了解 Linux 中虚拟文件系统(VFS)的知识,理解有关“inode”、“dentry”、“文件”、“超级块”和数据块的概念。
理解在 VFS 内挂载文件系统的过程。
了解各种文件系统类型,并理解具有物理支持(在磁盘上)和没有物理支持的文件系统之间的区别。
1.注册和注销myfs文件系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
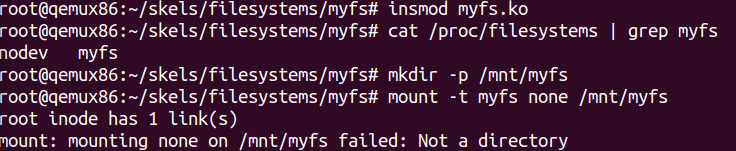
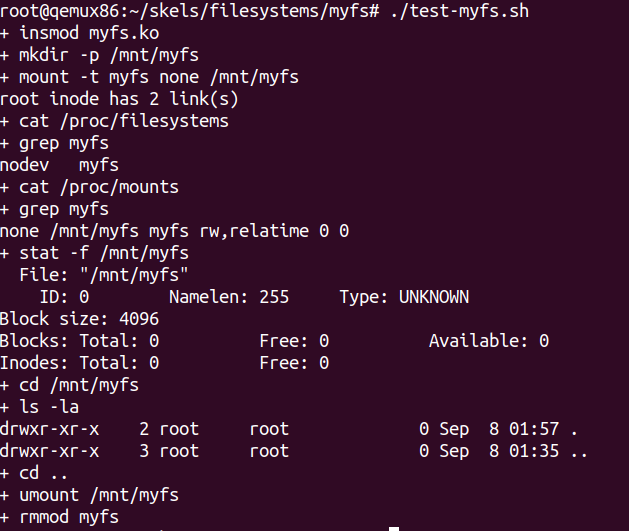
staticstruct dentry *myfs_mount(struct file_system_type *fs_type, int flags, constchar *dev_name, void *data) { /* TODO 1/1: call superblock mount function */ return mount_nodev(fs_type, flags, data, myfs_fill_super); } /* TODO 1/6: define file_system_type structure */ staticstructfile_system_typemyfs_fs_type = { .owner = THIS_MODULE, .name = "myfs", .mount = myfs_mount, .kill_sb = kill_litter_super, }; /* TODO 1/1: register */ err = register_filesystem(&myfs_fs_type); /* TODO 1/1: unregister */ unregister_filesystem(&myfs_fs_type);
/* TODO 5/1: Init i_ino using get_next_ino */ inode->i_ino = get_next_ino();
/* TODO 6/1: Initialize address space operations. */ inode->i_mapping->a_ops = &minfs_aops;
if (S_ISDIR(mode)) { /* TODO 3/2: set inode operations for dir inodes. */ inode->i_op = &simple_dir_inode_operations; inode->i_fop = &simple_dir_operations;
/* TODO 5/1: use myfs_dir_inode_operations for inode * operations (i_op). */ inode->i_op = &minfs_dir_inode_operations;
/* TODO 3/1: directory inodes start off with i_nlink == 2 (for "." entry). * Directory link count should be incremented (use inc_nlink). */ inc_nlink(inode); }
/* TODO 6/4: Set file inode and file operations for regular files * (use the S_ISREG macro). */ if (S_ISREG(mode)) { inode->i_op = &minfs_file_inode_operations; inode->i_fop = &minfs_file_operations; }
return inode; } staticintminfs_fill_super(struct super_block *s, void *data, int silent) { structminfs_sb_info *sbi; structminfs_super_block *ms; structinode *root_inode; structdentry *root_dentry; structbuffer_head *bh; int ret = -EINVAL;
/* Set block size for superblock. */ if (!sb_set_blocksize(s, MINFS_BLOCK_SIZE)) goto out_bad_blocksize;
/* TODO 2/3: Read block with superblock. It's the first block on * the device, i.e. the block with the index 0. This is the index * to be passed to sb_bread(). */ bh = sb_bread(s, MINFS_SUPER_BLOCK); if (bh == NULL) goto out_bad_sb;
/* TODO 2/1: interpret read data as minfs_super_block */ ms = (struct minfs_super_block *) bh->b_data;
/* TODO 2/2: check magic number with value defined in minfs.h. jump to out_bad_magic if not suitable */ if (ms->magic != MINFS_MAGIC) goto out_bad_magic;
/* TODO 2/2: fill super_block with magic_number, super_operations */ s->s_magic = MINFS_MAGIC; s->s_op = &minfs_ops;
/* TODO 2/2: Fill sbi with rest of information from disk superblock * (i.e. version). */ sbi->version = ms->version; sbi->imap = ms->imap;
/* allocate root inode and root dentry */ /* TODO 2/0: use myfs_get_inode instead of minfs_iget */ root_inode = myfs_get_inode(s, MINFS_ROOT_INODE, S_IFDIR | S_IRWXU | S_IRGRP | S_IXGRP | S_IROTH | S_IXOTH); if (!root_inode) goto out_bad_inode;
root_dentry = d_make_root(root_inode); if (!root_dentry) goto out_iput; s->s_root = root_dentry;
/* Store superblock buffer_head for further use. */ sbi->sbh = bh;
/* TODO 4/2: Read block with inodes. It's the second block on * the device, i.e. the block with the index 1. This is the index * to be passed to sb_bread(). */ if (!(bh = sb_bread(s, MINFS_INODE_BLOCK))) goto out_bad_sb; /* TODO 4/1: Get inode with index ino from the block. */ mi = ((struct minfs_inode *) bh->b_data) + ino;
/* TODO 4/2: Fill dir inode operations. */ inode->i_op = &simple_dir_inode_operations; inode->i_fop = &simple_dir_operations;
/* TODO 4/1: Directory inodes start off with i_nlink == 2. * (use inc_link) */ inc_nlink(inode); /* TODO 4/1: uncomment after the minfs_inode is initialized */ mii->data_block = mi->data_block;
/* Free resources. */ /* TODO 4/1: uncomment after the buffer_head is initialized */ brelse(bh); //brelse(bh); unlock_new_inode(inode);
staticconststructsuper_operationsminfs_ops = { .statfs = simple_statfs, .put_super = minfs_put_super, /* TODO 4/2: add alloc and destroy inode functions */ .alloc_inode = minfs_alloc_inode, .destroy_inode = minfs_destroy_inode, /* TODO 7/1: = set write_inode function. */ .write_inode = minfs_write_inode, };