
FIO 测试学习文档
次访问
FIO测试 学习文档
Job File 配置文件执行 FIO 测试
通过编写一个ini格式的Job File来执行FIO测试,使用fio jobfile.fio完成测试
[global] 常用参数以及说明
| 参数名 | 取值 | 作用说明 |
|---|---|---|
iodepth_batch_complete |
8 |
io请求过来后,能retrieve获得的最多请求数,即当io请求提交后,取出处理的io请求数 |
iodepth_batch |
16 | io队列请求丢过来后,积攒到16个io请求后立即提交,一般是iodepth的值 |
ioengine |
libaio |
使用 Linux 的异步 I/O 引擎(libaio),适合测试真实负载环境 |
rw |
read |
I/O 模式为顺序读(sequential read),用于测试读取吞吐能力,除了read还可以取值write,rw,randread,randwrite,randrw |
bs |
1M |
每次 I/O 操作的块大小为 1MB,影响数据吞吐与 IOPS |
size |
10G |
每个 job 的总 I/O 数据量上限为 10GB(如果不是基于时间模式才生效) |
time_based |
1 |
启用基于时间的测试模式,不以数据总量决定测试结束 |
runtime |
30 |
测试持续时间为 30 秒 |
norandommap |
1 |
禁用随机 I/O 映射表,减少运行时开销,每个块可能多次读写可能不使用 |
randrepeat |
1 |
使用固定的随机种子,每次运行能复现相同的随机序列 |
group_reporting |
1 |
合并组内 job 的测试结果,统一输出 |
iodepth |
8 |
设置每个 job 的 I/O 队列深度为 8,控制并发请求数量,线程一次提出8个I/O请求 |
direct |
1 |
启用 Direct I/O,跳过文件系统缓存,直接访问存储设备 |
numjobs |
10 |
启动 10 个并发 job,提高测试负载并模拟多线程环境 |
| thread | 1 | 使用线程创建job,适合numjobs值很大的情况,模拟多应用高并发场景,但要求测试复杂度较低,需要处理同步问题,容易崩溃 |
| ramp_time | 30 | 跑每个job之前进行的预热时间 |
[file] 常用参数以及说明
| 参数名 | 取值 | 作用说明 |
|---|---|---|
filename |
/mnt/glfs/file0 |
指定测试文件的路径,这里是挂载在 /mnt/glfs/ 下的一个文件,通常为分布式文件系统路径 |
命令行格式参数与说明
通过命令行参数执行 FIO 测试,便于与shell脚本结合使用
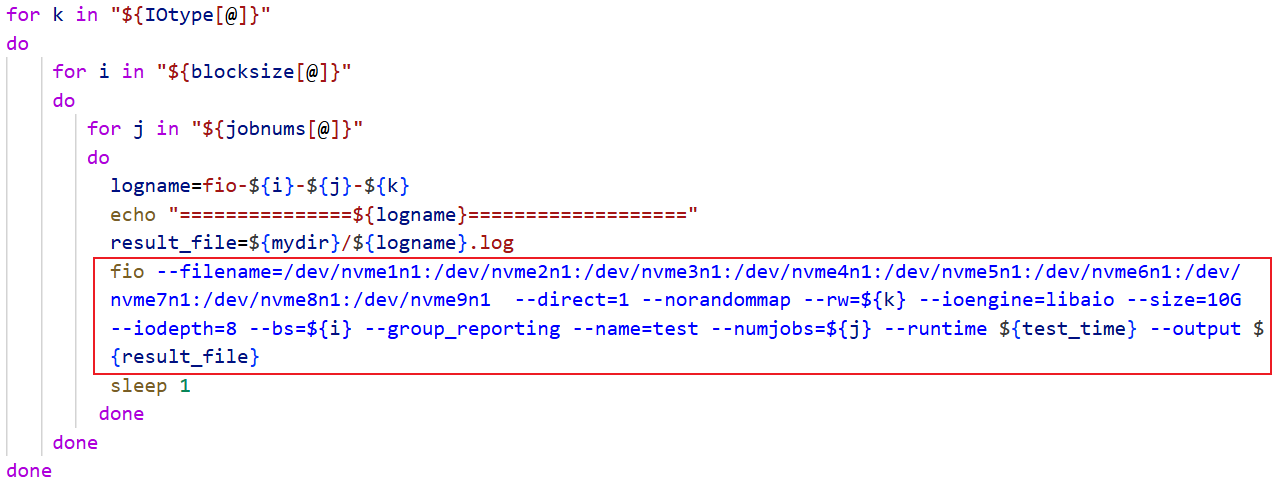
命令行参数含义如下:
--filename=...:测试设备,这里是多个 NVMe 磁盘。
--direct=1:绕过文件系统缓存,直接 I/O。
--norandommap:防止随机访问映射(提高随机性)。
--rw=${k}:I/O 模式,传入变量 k,如 read、write。
--ioengine=libaio:使用异步 I/O 引擎。
--size=10G:每个 job 的 I/O 数据大小。
--iodepth=8:每个 job 的 I/O 队列深度。
--bs=${i}:块大小,传入变量 i。
--group_reporting:报告时合并所有 job 的结果。
--name=test:任务名。
--numjobs=${j}:并发 job 数量。
--runtime=${test_time}:测试时间(单位为秒),变量 test_time 应该事先定义。
--output=${result_file}:将结果输出到指定日志文件。
fio 结果解读
1 | fio -filename=/dev/vdb -direct=1 -iodepth 32 -thread -rw=randrw -rwmixread=70 -ioengine=libaio -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=testfio |
1 | testfio: (g=0): rw=randrw, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=32 |
IOPS: 每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一;
Bw: 带宽,带宽是指平均每秒读写的数据量。在同样的延时指标下,增加并发可以提高吞吐量。
存储性能的好坏,需要IOPS、延迟、带宽三者结合来看
1 | slat (usec): min=2, max=397853, avg=44.61, stdev=1202.15 |
I/O延迟包括三种:slat,clat,lat:关系是 lat = slat + clat;
- slat 表示fio submit某个I/O的延迟;
- clat 表示fio complete某个I/O的延迟;
- lat 表示从fio将请求提交给内核,再到内核完成这个I/O为止所需要的时间;
1 | lat (usec) : 100=0.01%, 250=0.01%, 500=0.06%, 750=0.45%, 1000=0.62% |
- 这组数据表明lat(latency:延迟 )的分布;有0.01%的request延迟<100us,有0.01%的 100us < request lat < 250us,有0.06%的 250us < request lat < 500us,以此类推;
1 | cpu : usr=1.74%, sys=3.50%, ctx=47684, majf=0, minf=10 |
- usr:表示用户空间进程;
- sys:表示内核空间进程;
- 因为上下文切换导致的主要和次要页面失败的用户/系统 CPU使用百分比。因为测试被配置的使用直接IO,因此有很少的页面失败:
1 | IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% |
- iodepth设置用来控制在任何时间有多少IO分发给系统。这完全是应用方面的,意味着它和设备的IO队列做不同的事情,iodepth设置为1因此IO深度在100%的时间里一直是一个1;
1 | Run status group 0 (all jobs): |
- bw=这组进程的总带宽,每个线程的带宽(设置了numjobs>1这里会很明显);
- io=这组总io大小;
- 线程的最小和最大时间;
1 | Disk stats (read/write): |
- ios:读/写 I/O 次数
- merge:合并的请求数
- ticks:花在 I/O 上的时间(ms)
- in_queue:请求在队列里的时间(ms)
- util:磁盘利用率(100% 说明磁盘一直在忙)
四个关键参数
bw(带宽)
- 顺序 I/O 时:带宽是核心指标(HPC 大文件通常看 GB/s)
- 随机 I/O 时:带宽 + IOPS 结合看
- 判断合理性 → 和硬件理论上限比,例如 NVMe 单盘顺序写可达 3.5GB/s,集群可叠加。
iops
- 小块随机 I/O 的核心指标
- HPC 元数据测试或数据库场景才特别看这个
- 和理论值比:NVMe 可到 700k IOPS(4KB 随机读),集群按并行度成倍增加。
延迟(slat / clat / lat)
slat= 提交延迟(fio 发出请求到内核调度的时间)clat= 完成延迟(存储设备处理时间)lat= 总延迟(两者之和)- 重点看 平均值 和 高百分位数(如 99.99th)
- 判断合理性 → HPC 顺序 I/O 延迟在 ms 级是正常,小块随机 NVMe 应在 100µs~1ms 内。
百分位延迟
- HPC 场景需要看尾延迟(tail latency),因为并行任务很怕极端慢请求。
- 如果 99.99% 延迟明显高于平均值很多,说明系统在高并发下有抖动问题。
影响四个关键参数的主要 fio 参数
| 指标 | 关键影响参数 | 说明 |
|---|---|---|
| 带宽 (bw) | bs(块大小)、iodepth、numjobs、rw(读写模式) |
大块顺序 I/O 通过较大 bs 和 iodepth 来提升吞吐;numjobs 多进程并发可叠加带宽。 |
| IOPS | bs、iodepth、numjobs、rw |
小块随机 I/O 依赖更深队列 (iodepth) 和更多并发 (numjobs) 才能达到高 IOPS。 |
| 延迟 (slat, clat, lat) | iodepth、rw, ioengine |
iodepth 增大会带来排队延迟;ioengine(如 libaio vs sync)影响请求提交和完成方式,影响延迟。 |
| 百分位延迟 | 同上 + iodepth_batch_complete, rate_iops, rate |
控制批量完成和速率限制参数会影响尾延迟表现,调节请求节奏,避免峰值拥塞。 |
HPC 分布式存储系统中影响这四指标的因素
硬件相关
- 存储介质类型:NVMe SSD、HDD、持久内存(PMEM)等带宽和延迟天差地别。
- 网络带宽和延迟:分布式存储中,网络往往成为瓶颈,影响总体带宽和延迟。
- 缓存策略:客户端缓存、服务器端缓存会降低实际 I/O 延迟,提高带宽。
软件/协议相关
- 并行访问算法:
- 文件分条(striping)、条带大小(stripe size)
- 数据复制策略(副本数、纠删码参数)
- 并发调度策略(请求合并、重排)
- I/O 协议栈:
- NFS, SMB, Lustre, BeeGFS 等协议处理效率和并发能力差异
- TCP/IP 堆栈优化,RDMA 等低延迟传输方式
- 负载均衡:
- 多客户端多请求分配到不同存储节点,均衡访问才能保持带宽和低延迟。
总结
| 指标 | HPC存储影响因素(示例) | 典型调优建议 |
|---|---|---|
| bw | 硬件带宽、网络带宽、并发数、条带大小 | 大块顺序读写,提升 bs、iodepth、numjobs |
| iops | NVMe能力、并行请求数、负载均衡 | 增加随机小块 iodepth 和 numjobs,用异步 ioengine |
| 延迟 | 协议栈效率、存储介质响应时间、队列长度 | 适当控制 iodepth,避免队列过深导致排队延迟 |
| 尾延迟 | 突发负载、缓存失效、网络抖动 | 使用 iodepth_batch_complete 等批量参数,限速避免过载 |
读写混合测试(randrw)的具体流程
举例randrw + iodepth=16 + numjobs=1:
- 准备阶段
- fio打开目标文件
/tmp/testfile,文件大小100M。 - 根据
bs=4k,文件被切成约 25,600 个块(100M/4k)。
- fio打开目标文件
- 执行阶段
- fio的单线程循环:
- 它随机选择一个块(因为是
randrw,随机读写)。 - 根据
rwmixread=70,它有70%概率选择读,30%概率选择写。 - 提交一个异步I/O请求到操作系统(通过
libaio)。
- 它随机选择一个块(因为是
- 同时,它不会等第一个请求完成就停住,而是会继续提交请求,直到挂起的请求数达到
iodepth=16。 - 当某个I/O完成,线程会收到通知,然后提交下一个请求,保持挂起请求数量稳定在16左右。
- fio的单线程循环:
- 总结
- 这样,fio的单线程模拟了一个深队列、高并发的I/O负载。
- 存储设备能同时处理多个请求,提高吞吐量。
- fio收集带宽、IOPS、延迟等指标,反映设备在这种负载下的表现。
示例 FIO 代码仓库
The StorPool FIO Test Suite 这个仓库提供基于FIO的块存储性能测试脚本,专为分布式存储系统(如StorPool集群)设计,支持在HPC环境中运行多节点测试。包括预定义的测试模板,适用于随机/顺序读写基准,适合分布式块存储的性能评估。仓库中有template目录下的.fio配置文件模板。
axboe/fio仓库(FIO官方仓库 FIO工具的官方GitHub仓库,examples/目录下有大量通用FIO job文件示例。虽然不是专为HPC分布式存储设计,但许多配置(如SSD或NVMe测试)可以修改用于分布式环境(如在HPC集群的多节点并行运行)。例如,ssd-steady.fio适用于高性能存储基准,可结合MPI或脚本实现分布式测试。
distributed-system-analysis/pbench仓库 pbench工具集中的FIO基准脚本,专为存储性能测试设计,支持HPC环境下的自动化测试,包括随机/顺序工作负载和统计计算。适用于分布式系统,如在集群中测试文件系统I/O。文档中描述了如何配置FIO参数以模拟HPC场景。
ls1intum/storage-benchmarking仓库 使用FIO测试容器化环境中的I/O性能,适用于分布式存储系统(如Kubernetes集群中的HPC应用)。仓库提供预定义的job配置,适合基准测试分布式存储的性能比较。