
MLPerf使用
次访问
MLPerf 学习
MLPerf 是一个业界标准的机器学习性能基准套件(benchmark suite)
它的目标是让不同硬件平台(CPU/GPU/TPU/ASIC)、框架(TensorFlow、PyTorch 等)和系统在 统一的工作负载 下进行公平的对比,从而衡量不同硬件/系统在标准ML任务上的性能
一 MLPerf 概念
定位:类似于CPU中的SPEC,存储中的fio,MLPerf是机器学习中的基准测试。
作用:旨在对硬件、软件和服务的训练和推理性能进行无偏评估。
MLPerf 主要解决的问题:
硬件对比
比如:NVIDIA A100 vs H100、Intel CPU vs AMD CPU、Google TPU vs Habana Gaudi
大家都跑同样的模型(ResNet-50、BERT、DLRM 等),就能公平比较性能。
系统优化对比
不只是 GPU/TPU,还包括 存储、网络、分布式训练框架、编译优化器 等。
比如 NCCL vs OneCCL,PyTorch vs TensorFlow,InfiniBand vs Ethernet。
统一标准
和 SPEC(CPU)、TPC(数据库性能)类似,MLPerf 是 ML 领域的统一标尺。
结果要符合精度门槛(accuracy target)、固定数据集和 batch size,保证公平。
基准测试类别
- MLPerf Training:Training基准套件测量系统训练模型达到目标质量指标的速度。
- MLPerf Training HPC
- MLPerf Inference:Inference基准套件测量系统处理输入和使用训练模型生成结果的速度。
- MLPerf Inference Datacenter
- MLPerf Inference Edge
- MLPerf Inference Mobile
- MLPerf Inference Tiny
- MLPerf Storage:MLPerf存储基准测试套件测量存储系统在训练模型时提供训练数据的速度。
- MLPerf Client:用于评估大型语言模型(LLMs)和其他 AI 工作负载在个人计算机上的性能——从笔记本电脑和台式机到工作站。通过模拟真实世界的 AI 任务,它提供了清晰的指标,以便了解系统处理生成性 AI 工作负载的能力。
- MLPerf Automotive:用于测量旨在用于汽车的计算机性能,包括高级驾驶辅助系统/自动驾驶(ADAS/AD)和车载信息娱乐(IVI)嵌入式系统。主要的关键绩效指标是延迟,因为汽车系统是实时的,且通常需要功能安全。
- AlgoPerf Training Algorithms:算法基准测试衡量通过更改基础训练算法(例如优化器或超参数)来提高神经网络模型训练速度,以达到给定的目标性能。
- AlLuminate:AILuminate基准评估一般聊天机器人生成AI系统的安全性,以帮助指导开发,告知购买者和消费者,并支持标准机构和政策制定者。
- MLPerf Training:Training基准套件测量系统训练模型达到目标质量指标的速度。
测试结果基础概念:
Queries(查询):指的是一个 推理请求,即向模型提交一个输入数据(例如一张图片、一段文本)并获取模型输出的过程。查询(Query) = 输入数据 + 推理任务。
每个查询通常包括
- 输入数据:例如一张图片、一段音频、一段文本
- 模型推理:将输入数据传递给模型,运行推理
- 输出结果:模型生成的预测结果(例如分类标签、生成文本)
QPS(Queries Per Second):系统每秒能够处理多少个查询(推理请求)
QPS 描述的是 推理应用 的性能指标,而不是模型本身的指标。它衡量的是整个推理系统的吞吐量
- 如果 QPS = 100,表示系统每秒可以处理 100 个推理请求
- 如果 QPS = 50,表示系统每秒可以处理 50 个推理请求。
- 这个值越高越好,表明系统能够在单位时间内处理更多请求
Mean(Mean Latency,平均延迟):表示系统处理一个任务(查询/推理请求)平均需要多长时间
- MEAN 越低,说明系统处理任务的速度越快。
测试场景类别:
SingleStream(单流):模拟单个用户推理请求的场景
每次处理 一个输入数据(例如一张图片、一段文本), 且 输入数据是逐张/逐条处理的。
举个例子,有100张图片,一个图片执行一次查询,每个图片逐张执行一次查询,总共执行100次。- 测试目标: 评估系统处理 单个任务(/查询) 的速度(延迟)
- 关键指标:延迟(Latency)
- 适用场景:对延迟敏感的应用,例如,实时图像分类,实时语音识别,自动驾驶中的实时目标检测
MultiStream(多流):模拟多个用户同时请求的场景
每个用户请求都是独立执行的。相当于多个 SingleStream 加在一起,但多个请求会同时并发执行
类似于OS单个进程和多个进程- 测试目标: 评估系统在同时处理多个并发请求 时的性能
- 关键指标: 吞吐量(Throughput)& 延迟(Latency)
- 适用场景:对吞吐量和延迟都有要求的应用,例如,多用户语音助手,多摄像头监控系统
Offline(离线):模拟单用户批量处理的场景
系统一次性处理大量输入数据(例如一批图片、一段长文本)来执行一次查询(推理请求)
由于模型一般地都支持一次性输入多个数据来执行一次查询,所以离线模式研究多个输入下模型的处理能力,这个瓶颈就在QPS
举个例子,有100张图片,给模型一次输入20张,然后模型一次推理后,输出20张的结果,然后进入下一个批处理周期,直到处理完成- 测试目标:评估系统处理 大量任务 的能力(吞吐量)
- 关键指标: 吞吐量(Throughput)
- 适用场景:对吞吐量要求高、对延迟不敏感的应用,例如,批量图像处理,大规模文本生成,离线数据分析
Server(服务器):模拟服务器端推理的场景
系统需要同时处理多个并发请求,并在规定时间内返回结果
- 关键指标: 吞吐量(Throughput)& 延迟(Latency)
- 适用场景:服务器端推理应用,例如,云端的图像分类服务,在线的语音识别服务,实时推荐系统
二 MLPerf 使用流程
1 MLPerf Inference
测试计算机视觉中图像分类和检测的性能
测试环境:
- 机器:Google Colab
- 基准模型:mobilenet、resnet50
- 模型框架:onnx
- 场景:视觉vision(图像分类)
- 数据集:fakeimagent
测试步骤:
克隆MLPerf Inference项目库
1
2
3
4git clone https://github.com/mlperf/inference.git
cd inference/vision/classification_and_detection
import os
root = os.getcwd()安装必要的依赖库
1
2
3
4
5
6
7apt-get install python3-dev
apt-get install cmake
pip install pytest
pip install numpy
pip install scipy
pip install pybind11
pip install onnxruntime pycocotools opencv-python执行安装脚本
1
2cd ../../loadgen; CFLAGS="-std=c++14" python setup.py develop; cd {root}
python setup.py develop安装成功应该在最后会显示
1
2Using /usr/local/lib/python3.12/dist-packages
Finished processing dependencies for mlperf-inference==0.1.0下载模型
1
2
3
4
5# 下载 mobilenet 模型
wget -q https://zenodo.org/record/3157894/files/mobilenet_v1_1.0_224.onnx
# mobilenet 为 resnet50 模型的轻量级模型,以降低模型复杂性和计算负担
# 下载 resnet50 模型
wget -q https://zenodo.org/record/2592612/files/resnet50_v1.onnx其他模块链接地址https://github.com/mlcommons/inference/tree/master/vision/classification_and_detection
下载数据集
1
2
3
4# 在本测试中,使用 MLPerf 提供的 tools/make_fake_imagenet.sh 工具创建一个假装为 imagenet 的小型假数据集
bash ./tools/make_fake_imagenet.sh
# 运行上述命令后,将在 /vision/classification_and_detection 文件夹中创建一个 fakeimagenet 文件夹,里面包含 val 文件夹和 val_map.txt 文件,val 文件夹中存放着 8 张假的图像数据集
# 通常需要下载 imagenet2012/valiation 进行图像分类,或下载 coco2017/valiation 进行对象检测其他数据集的链接和说明地址https://github.com/mlcommons/inference/tree/master/vision/classification_and_detection
添加环境变量
1
2
3import os
os.environ['MODEL_DIR'] = root
os.environ['DATA_DIR'] = os.path.join(root, "fake_imagenet")对于 mlperf 提交的查询数、时间、延迟和百分位数,一般默认使用的设置。这个测试收中参考了官方教程,传递了一些额外的选项来让测试进展得更快。 run_local.sh 将查找环境变量 EXTRA_OPS 并将其添加到参数中。 还可以在命令行中添加其他参数。 以下选项将基准测试的运行时间限制为 10 秒,并添加准确性报告。
1
os.environ['EXTRA_OPS'] ="--time 10 --max-latency 0.2"
把
remove_initializer_from_input.py文件放到classification_and_detection文件夹
文件链接地址为https://github.com/microsoft/onnxruntime/blob/main/tools/python/remove_initializer_from_input.py
执行以下命令
1
python remove_initializer_from_input.py --input ./mobilenet_v1_1.0_224.onnx --output ./mobilenet_v1_1.0_224.onnx
再运行基准测试(mobilenet模型)
1
./run_local.sh onnxruntime mobilenet cpu --scenario SingleStream
--scenario {SingleStream,MultiStream,Server,Offline}选择要测试基准的场景

输出结果保存在 output 文件夹中
1
ls ./output/onnxruntime-cpu/mobilenet
测试结果存储在
mlperf_log_summary.txt文件中,可查看该日志文件中的内容获取测试结果1
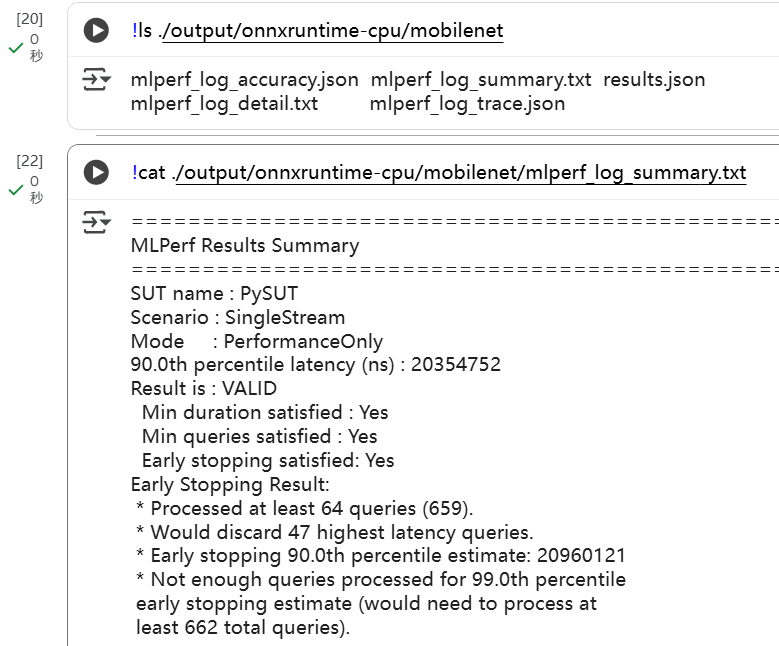
cat ./output/onnxruntime-cpu/mobilenet/mlperf_log_summary.txt
总结:
主要步骤:
- 安装MLPerf inference库和必要的依赖
- 下载模型
- 下载数据集
- 执行基准测试
基准测试应用程序使用 shell 脚本来简化命令行选项,用户可以选择后端、模型和设备
1 | !./run_local.sh |
测试结果:
- 基本信息
1 | SUT name : PySUT |
- SUT name:System Under Test(被测系统)的名字,这里叫
PySUT - Scenario:运行场景,这里是 SingleStream(模拟一条推理请求流)
- Mode:运行模式,这里是 PerformanceOnly,说明只测性能,不测精度
- 结果摘要
1 | 90.0th percentile latency (ns) : 20354752 |
- 90.0th percentile latency (ns):90 分位延迟,也就是 90% 的请求在 20,354,752 纳秒(约 20.3 ms)以内完成
- Result is : VALID:说明结果合规
- Min duration satisfied:测试时间达到最低要求
- Min queries satisfied:推理请求数量达到最低要求
- Early stopping satisfied:启用了早停机制,判定结果有效
- Early Stopping(早停机制)
1 | Early Stopping Result: |
- Processed at least 64 queries (659):实际处理了 659 次推理请求,超过最低 64 次的要求
- Would discard 47 highest latency queries:早停算法会丢掉最慢的 47 个请求,再估计分位数
- Early stopping 90.0th percentile estimate:估算的 90% 分位延迟是 20,960,121 ns(≈20.96 ms)
- Not enough queries for 99%:没有足够请求数(需要 ≥662),所以没法估算 99% 分位
- 性能统计
1 | QPS w/ loadgen overhead : 65.75 |
- QPS w/ loadgen overhead:带上 MLPerf LoadGen(负载生成器)的开销后,每秒处理 65.75 个请求
- QPS w/o loadgen overhead:纯粹推理请求处理速度,每秒 65.82 个请求
二者接近,说明 LoadGen 对性能影响不大。
- 延迟分布
1 | Min latency (ns) : 11783153 (~11.8 ms) |
- Min latency:最快的一次推理 ≈ 11.8 ms
- Max latency:最慢的一次推理 ≈ 26.8 ms
- Mean latency:平均 ≈ 15.2 ms
- 50% 分位:一半请求低于 ≈ 13.7 ms
- 90% 分位:90% 请求低于 ≈ 20.4 ms(这是主要考核指标)
- 95%/97%/99%/99.9% 分位:高百分位延迟,反映尾部性能(越低越好)
- 总结
- 系统 SingleStream 延迟中位数 ~13.7 ms,90% 分位 ~20.3 ms
- 吞吐量大概 65 QPS
- 结果 VALID,性能合格
- 延迟分布没有太大的长尾,尾延迟(99%)约 23 ms
2 MLPerf Storage
测试存储系统在训练模型时提供训练数据的速度
测试步骤:
安装依赖
1
2
3
4
5
6
7
8sudo apt update
sudo apt install python3-pip python3-venv libopenmpi-dev openmpi-common
python3.10 -m venv ~/.venvs/mlpstorage
source ~/.venvs/mlpstorage/bin/activate
python3 -m pip install --upgrade pip
git clone -b v2.0 https://github.com/mlcommons/storage.git
cd storage
pip3 install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple计算training datasize

1
2
3# 例如
mlpstorage training datasize -m unet3d --client-host-memory-in-gb 128 --max-accelerators 16 --num-client-hosts 2 --accelerator-type a100 --results-dir ~/mlps-results
# 计算在两台各有128 GB内存的客户端机器上运行的unet3d模型的最小数据集大小,总共模拟了8个A100加速器生成 training data

1
2
3# 例如,其中IP1和IP2是两个节点,一个是主机节点一个是客户端节点,在主机上执行命令即可
mlpstorage training datagen --hosts IP1,IP2 --model unet3d --num-processes 8 --data-dir /mnt/unet3d_data --param dataset.num_files_train=56000
# 生成56,000个unet3d工作负载的训练数据,将其放入unet3d_data目录,使用8个并行作业分布在2个节点上运行 Trainning 测试

1
2
3# 例如
mlpstorage training run --hosts 10.117.61.121,10.117.61.165 --num-client-hosts 2 --client-host-memory-in-gb 64 --num-accelerators 2 --accelerator-type h100 --model unet3d --data-dir unet3d_data --results-dir unet3d_results --param dataset.num_files_train=400
# 使用位于 unet3d_data 目录中的数据,对 unet3d 工作负载进行基准测试,使用2个分布在2个客户端主机上的 H100 加速器(IP 地址为 10.117.61.121 和 10.117.61.165),并将结果保存到 unet3d_results 目录中查看测试结果
1
2
3# 例如,这个脚本必须在主机节点(launcher client host)上运行
mlpstorage reports reportgen --out-dir ./results
# 将结果保存在results目录下
单机测试:使用U-Net3D模型,至少需要1张A100或H100
计算数据大小
1
2
3
4
5mlpstorage training datasize --model unet3d --client-host-memory-in-gb 32 --num-client-hosts 1 --max-accelerators 1 --accelerator-type h100
# --client-host-memory-in-gb 是指主机可用内存大小
# --num-client-hosts 是指节点数量,因为是单机测试所以设置为1
# --max-accelerators 是指可用的计算卡数量
# --accelerator-type 可选a100或h100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 结果说明
// 1.文件数量要求
RESULT: Minimum file count dictated by 500 step requirement of given accelerator count and batch size.
RESULT: Number of training files: 3500
/*
500 step requirement: MLPerf规定训练必须至少运行500个步骤(steps)
3500个文件: 基于1张A100 GPU的批处理大小和500步要求计算出的最小文件数
这确保有足够的数据让训练跑满500个iteration
*/
// 2.存储需求
RESULT: Total disk space required for training: 477.86 GB
/*
总共需要约478 GB的磁盘空间
平均每个文件大小:478 GB ÷ 3500 ≈ 140 MB
*/
// 3.数据组织
RESULT: Number of training subfolders: 0
/* 所有文件将放在同一个目录下,不使用子文件夹结构 */生成训练数据
1
2
3mlpstorage training datagen --hosts 127.0.0.1 --num-processes 8 --model unet3d --data-dir unet3d_data --results-dir unet3d_results --param dataset.num_files_train=500
# --num-processes 是指使用的处理器数量,越多生成的越快,用lscpu看有多少个cpu数量
# dataset.num_files_train 是指训练文件数量
运行测试
1
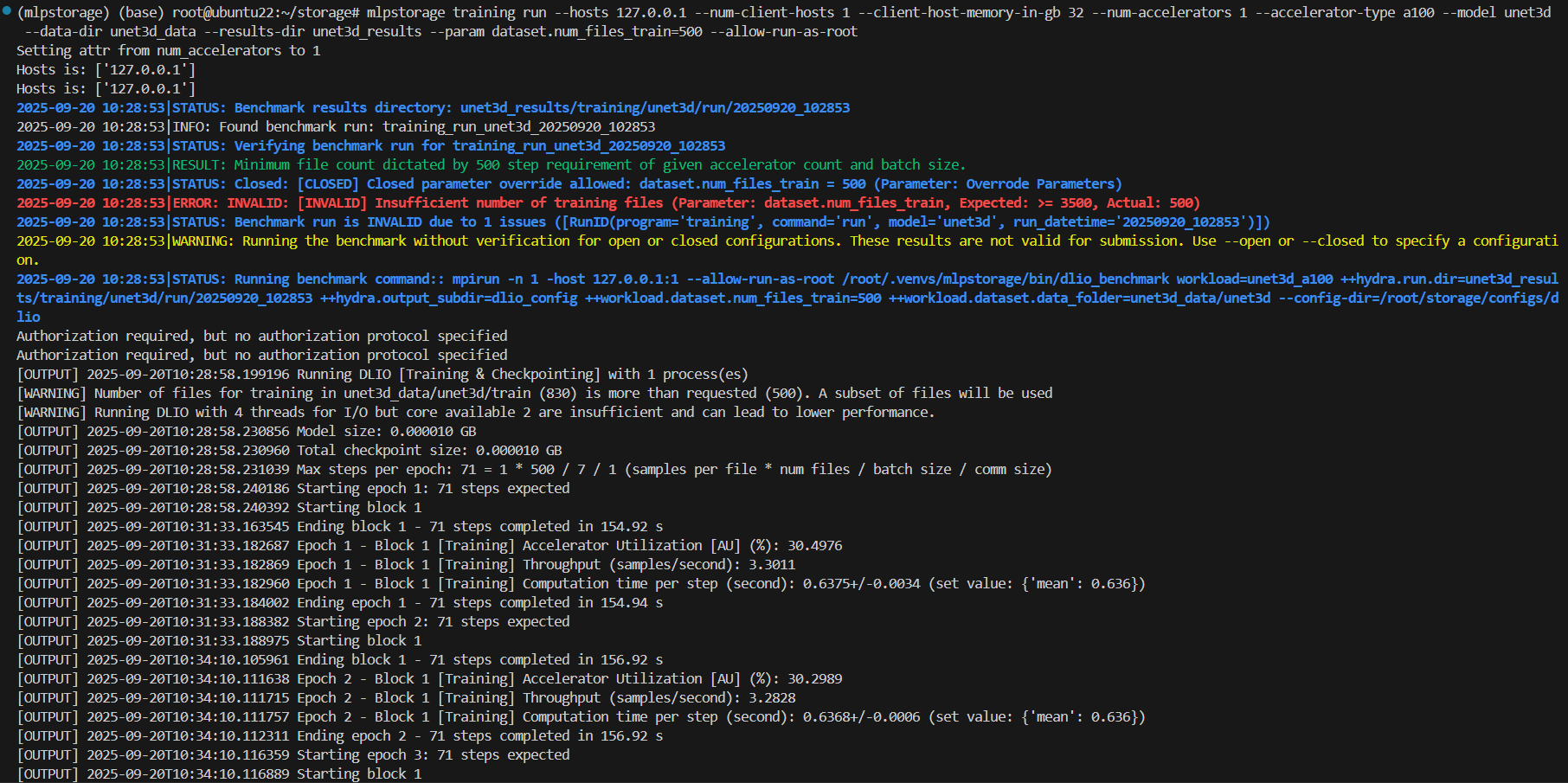
mlpstorage training run --hosts 127.0.0.1 --num-client-hosts 1 --client-host-memory-in-gb 32 --num-accelerators 1 --accelerator-type a100 --model unet3d --data-dir unet3d_data --results-dir unet3d_results --param dataset.num_files_train=500 --allow-run-as-root
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67// 结果说明
// 1. 配置验证结果
ERROR: INVALID: [INVALID] Insufficient number of training files
(Parameter: dataset.num_files_train, Expected: >= 3500, Actual: 500)
- 状态: 配置无效(INVALID)
- 原因: 文件数量不足,需要至少3500个文件
- 影响: 结果不能用于正式MLPerf提交,但测试依然运行
// 2. 运行模式
WARNING: Running the benchmark without verification for open or closed configurations.
These results are not valid for submission.
- 在非验证模式下运行
- 结果仅用于性能测试,不符合MLPerf提交标准
// 性能指标分析
// 1. 训练配置
Max steps per epoch: 71 = 1 * 500 / 7 / 1 (samples per file * num files / batch size / comm size)
/*
- 每个epoch步数: 71步 (500个文件 ÷ 7 batch size = 71步)
- 运行了5个epochs: 总共355步
- 每步时间: 约0.637秒
*/
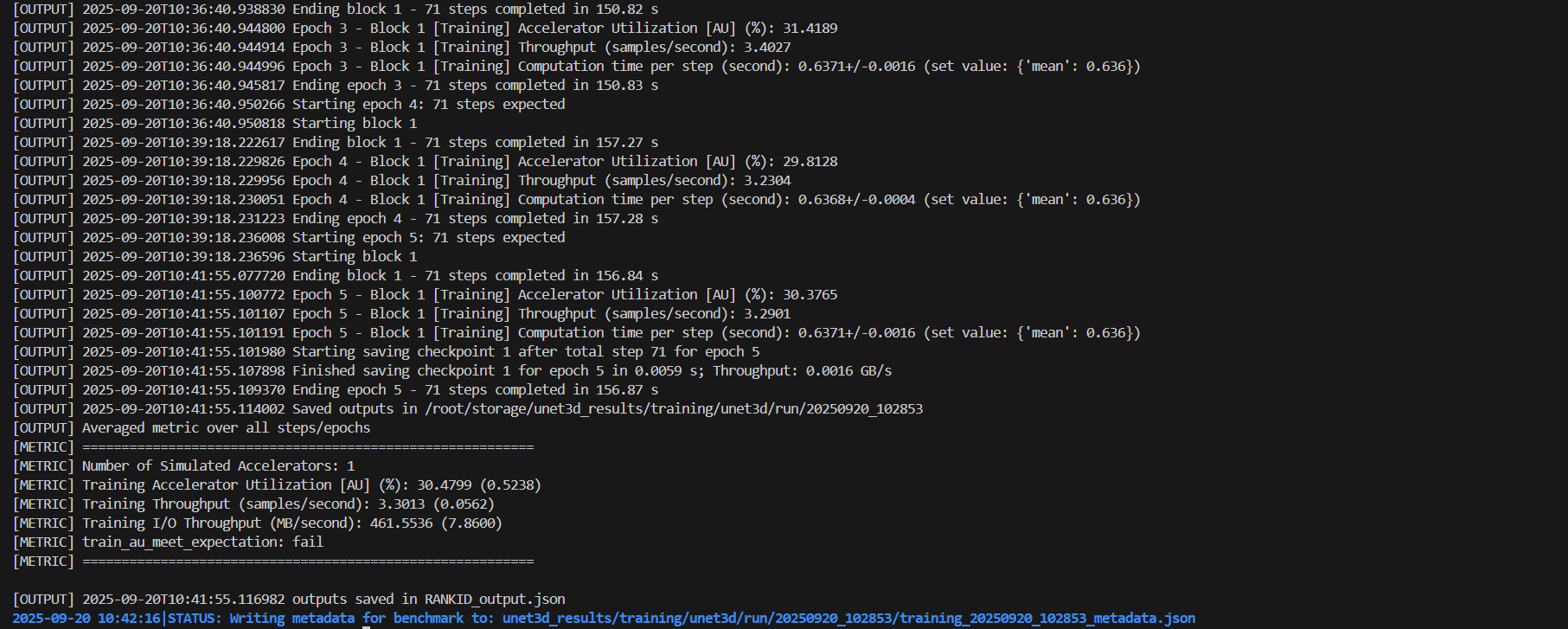
// 2. 关键性能指标
Training Accelerator Utilization [AU] (%): 30.48%
train_au_meet_expectation: fail
/*
GPU利用率 (AU - Accelerator Utilization)
- 平均GPU利用率: 30.48%
- 状态: 失败 - GPU利用率过低
- 问题: 存储I/O成为瓶颈,GPU等待数据
吞吐量表现
Training Throughput (samples/second): 3.30
Training I/O Throughput (MB/second): 461.55
- 训练吞吐量: 3.30 样本/秒
- I/O吞吐量: 461.55 MB/秒
*/
// 性能问题分析
// 1. GPU利用率低的原因
Epoch 1-5 AU范围: 29.81% - 31.42%
平均计算时间: 0.6368±0.0034秒/步
- 存储I/O瓶颈: GPU经常等待数据加载
- 数据管道效率低: 数据预处理跟不上GPU消耗速度
// 2. 系统资源警告
[WARNING] Running DLIO with 4 threads for I/O but core available 2 are insufficient
and can lead to lower performance.
- CPU核心不足: 只有2个可用核心,但需要4个I/O线程
- 建议: 增加CPU资源或减少I/O线程数
// 3. 数据集问题
[WARNING] Number of files for training in unet3d_data/unet3d/train (830) is more than requested (500).
A subset of files will be used
- 实际生成了830个文件,但只使用了500个
- 建议清理多余文件或使用完整数据集
//检查点和模型信息
Model size: 0.000010 GB
Total checkpoint size: 0.000010 GB
Checkpoint save time: 0.0059 s
Checkpoint throughput: 0.0016 GB/s
- 模型很小(仅10KB),主要瓶颈在数据I/O
- 检查点保存速度正常
// 测试结果状态
- ✅ 功能性成功: 训练流程正常运行
- ✅ 数据加载正常: 数据读取和训练循环工作正常
- ❌ 性能不达标: GPU利用率过低 (30% vs 期望的>80%)
- ❌ 配置不合规: 文件数量不符合MLPerf规范
- ❌ 资源不足: CPU资源不足影响I/O性能